Kakao Unveils Performance of “Kanana-o,” Korea’s First Unified Multimodal Language Model Integrating Text, Voice, and Image

- Simultaneously understands and processes text, speech, and images... developed efficiently in a short period using model merging technology
- Competitive results in both Korean and English benchmarks, comparable to global models
- Evolving from text-centric AI to empathetic AI that sees, listens, and speaks like humans... Kakao plans ongoing research sharing to contribute to the AI ecosystem
[May 1, 2025] Kakao continues to strengthen its technological competitiveness with a new AI model.
The company has published the performance and development insights of its unified multimodal language model “Kanana-o” and audio language model “Kanana-a” through its official tech blog.
“Kanana-o” is the first model in Korea capable of simultaneously understanding and processing multiple types of information—text, speech, and images. The model can process input in any combination of these modalities and is designed to respond appropriately with either text or natural-sounding speech, depending on the context.
Using model merging technology, Kakao efficiently developed Kanana-o by integrating “Kanana-v,” which specializes in image processing, and “Kanana-a,” which specializes in audio comprehension and generation. After merging, the model underwent joint training, learning image, audio, and text data simultaneously to connect visual and auditory information with language. Through this development process, Kanana-o evolved beyond traditional large language models (LLMs) to incorporate advanced image understanding, speech recognition and synthesis, and even emotion recognition in audio.
Thanks to its speech emotion recognition capabilities, Kanana-o accurately interprets users’ intentions and provides emotionally appropriate, context-aware responses. It analyzes non-verbal signals like intonation, speech patterns, and voice tremors, and generates voice responses that sound natural and emotionally nuanced within the flow of conversation.
The model is further refined using large-scale Korean datasets, carefully reflecting Korean-specific speech structures, intonations, and verb endings. Notably, it can recognize regional dialects (e.g., Jeju and Gyeongsang), and convert them into standard Korean to produce fluent, natural responses. To further enhance its capabilities, Kakao is currently developing its own Korean speech tokenizer—a tool that breaks down audio signals into smaller units.
In addition, the model supports streaming-based speech synthesis, enabling responses with minimal latency for a smoother user experience. For example, if you input “Create a fairy tale that matches this picture” along with an image, Kanana-o understands the voice, analyzes the user’s tone and emotions, and generates a natural and creative story in real time.
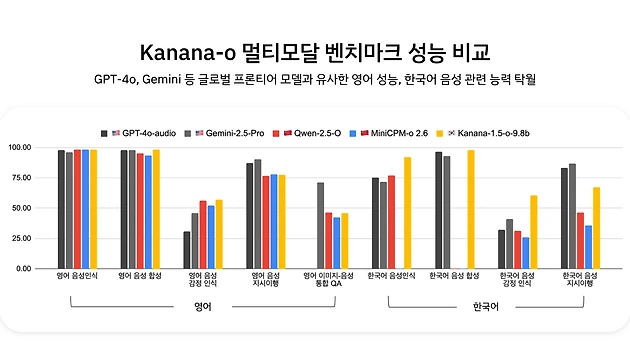
Kanana-o achieved a performance level comparable to the best global models in both Korean and English benchmarks, with a significant advantage in the Korean benchmark. In particular, in terms of emotion recognition, it recorded a significant gap in both Korean and English, proving the potential of an AI model that can understand and communicate emotions. Kanana-o also achieved strong performance in the “Image–Voice QA” task, which requires integrated understanding of both image and voice, confirming its global competitiveness as an integrated multimodal language model.
In the future, Kakao plans to continue research and development with goals such as enhancing multi-turn conversation handling, improving full-duplex (i.e., simultaneous bidirectional data transmission) capabilities, and ensuring safety to prevent inappropriate responses. Through this, Kakao aims to innovate the user experience in multi-voice conversation environments and realize natural interactions closer to real conversations.
Kakao Kanana Performance Lead Kim Byeong-hak stated, “The Kanana model is evolving beyond traditional text-based AI by integrating complex information to see, hear, speak, and empathize like humans. Based on its unique multimodal technology, we are strengthening our AI technology competitiveness and plan to continue contributing to the development of the domestic AI ecosystem through the sharing of continuous research outcomes.”
Kakao revealed its proprietary AI model lineup “Kanana” last year and shared the performance and development of language models, multimodal language models, and visual generation models through its official tech blog. In February this year, Kakao released the “Kanana Nano 2.1B” model as open-source on GitHub to kickstart the domestic AI ecosystem and also published a technical report on its self-developed language model “Kanana” on ArXiv. (E.O.D.)
Reference: Kakao Official Tech Blog
“Exploring Kanana-o, a multimodal language model that integrates images and voice”
- Press Release 발행일 2026.06.05 Kakao Launches Environmental Initiatives for World Environment Day, Including Eco-Friendly Campaign on Kakao Together
 #Kakao#World Environment Day
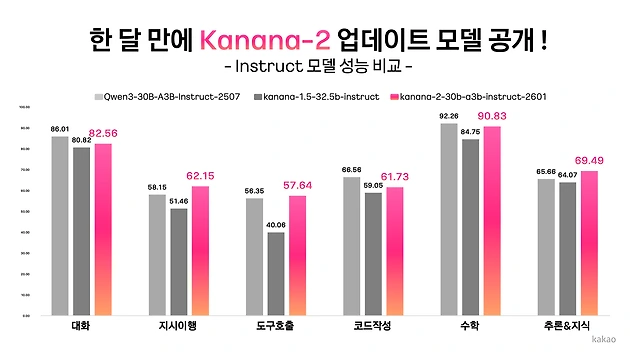
#Kakao#World Environment Day - Press Release 발행일 2026.01.20 Kakao Releases Four Additional Open-Source Versions of the Upgraded “Kanana-2” Model
 #kakao#Kanana
#kakao#Kanana - Press Release 발행일 2025.12.12 Kakao Unveils Performance of Two Advanced Multimodal Language Models
 #kakao#Multimodal Language Model
#kakao#Multimodal Language Model


