Kakao Releases Four Additional Open-Source Versions of the Upgraded “Kanana-2” Model

- Efficiency reinvented through MoE architecture along with segmented training stages, also significantly enhancing performance for Agentic AI implementation
- Runs smoothly on widely available GPUs at the NVIDIA A100 level, improving real-world usability
- Training underway for MoE-based ultra-large model “Kanana-2-155b-a17b” with hundreds of billions of parameters, showing performance comparable to Zhipu AI’s GLM-4.5-Air-Base
[January 20, 2026] Kakao (CEO Shina Chung) announced that the company has upgraded Kanana-2—its next-generation language model developed in-house—and has additionally released four versions as open source.
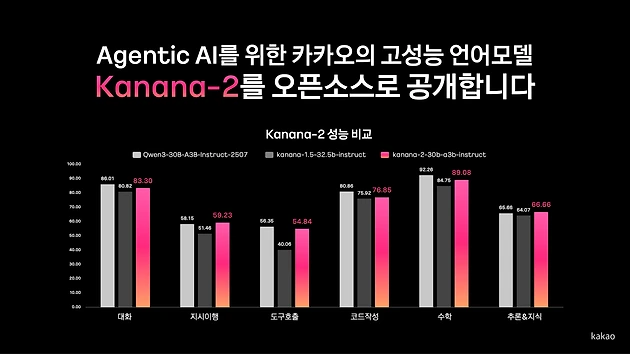
Kanana-2 was first released as an open-source language model on Hugging Face last December. Having demonstrated high performance and efficiency optimized for Agentic AI, Kakao has now followed up in just over a month with four newly upgraded models offering substantially improved capabilities.
#Practical performance on NVIDIA A100-class GPUs, with efficiency-driven MoE architecture and more granular training stages
The four newly released models boast not only high efficiency and cost-effective performance improvements but also significantly enhanced tool-calling capabilities essential for implementing practical Agentic AI. In particular, the models are optimized to run smoothly on widely available GPUs comparable to the NVIDIA A100 instead of requiring the latest ultra-high-cost infrastructure. This improves accessibility, enabling small and medium-sized enterprises as well as academic researchers to leverage high-performance AI without incurring significant costs.
At the core of the efficiency of Kanana-2 is its Mixture of Experts (MoE) architecture. While the total parameter size reaches 32 billion parameters (32B)—maintaining the high intelligence of a large-scale model—only 3 billion parameters (3B) are activated during inference depending on the task; thus dramatically improving computational efficiency. Kakao also developed multiple essential kernels for MoE training in-house, achieving faster training speeds and significantly reduced memory usage without performance loss.
Beyond architectural and data advancements, Kakao further refined the training process itself. A new mid-training stage was introduced between pre-training and post-training. Kakao applied a replay technique to prevent catastrophic forgetting wherein an AI model loses previously learned knowledge while learning new information. This addition enabled the model to acquire new reasoning capabilities while maintaining stable Korean language proficiency and general knowledge.
Kakao has released four model variants on Hugging Face based on these advances: base model, instruct model, thinking-specialized model, and mid-training research model. By also providing a base model suited for mid-training exploration, Kakao aims to contribute further to the open-source research ecosystem.
#Specialized for agentic AI: Aiming for global top-tier performance with 155B-parameter MoE model in training
Another key differentiator of the new Kanana-2 models is their specialization in agentic AI, which can perform real-world tasks beyond simple conversational AI.
Kakao significantly strengthened both instruction-following and tool-calling capabilities by intensively training on high-quality multi-turn tool-calling data, enabling the model to interpret complex user requests accurately and select and invoke appropriate tools autonomously. In performance evaluations, the model demonstrated clear advantages over comparable competitor Qwen-30B-A3B-Instruct-2507 across instruction-following accuracy, multi-turn tool-calling performance, and Korean language proficiency.
“The upgraded Kanana-2 reflects our in-depth consideration of how to implement practical Agentic AI without relying on costly infrastructure. By releasing a high-efficiency model that performs well even in common computing environments as open source, we hope to provide a new alternative for AI adoption by companies and contribute to the growth of Korea’s AI research and development ecosystem,” said Kanana Performance Lead Byung-hak Kim.
Meanwhile, Kakao is currently training Kanana-2-155b-a17b, an ultra-large-scale MoE-based model encompassing hundreds of billions of parameters. Despite being trained on only about 40% of the data used for Zhipu AI’s GLM-4.5-Air-Base model, it has demonstrated comparable performance on major benchmarks such as MMLU, which measures general model intelligence. It has also shown particularly strong performance in Korean question answering and mathematics. Moreover, Kakao is maximizing training efficiency by adopting an 8-bit training format—a next-generation high-efficiency format supported by NVIDIA’s latest Hopper GPUs—instead of the conventional 32-bit or 16-bit formats typically used in LLM training.
Moving forward, Kakao plans to continue developing foundation models targeting world-class performance and to introduce increasingly advanced AI capable of handling more complex agent-based scenarios. (E.O.D.)
[Reference]
* Kanana-2 open-source model download (Hugging Face)
https://huggingface.co/collections/kakaocorp/kanana-2
* Kanana-2 development story on the Kakao Tech Blog
- Press Release 발행일 2026.06.05 Kakao Launches Environmental Initiatives for World Environment Day, Including Eco-Friendly Campaign on Kakao Together
 #Kakao#World Environment Day
#Kakao#World Environment Day - Press Release 발행일 2025.12.19 Kakao’s Open-Source Release of “Kanana-2,” a Model Optimized for Agentic AI Implementation
 #kakao#Kanana
#kakao#Kanana

